When building an app, a developer might have to synchronize data with backend, for example, to implement offline mode. With small amounts of data, most apps don’t require specific techniques and the simplest solutions work well.
But when we’re speaking of thousands or more entities, issues might occur. Developers want to look into the matter and find a better solution, and if one doesn’t exist, they write it themselves. However, this would be the topic for another article.
This article is about how to provide fast performance, which is an essential requirement for product development. Let’s start by taking a short journey to the past to see the fastest mapping solution at the dawn of the 2010s.
The Objective-C era
The beginning of the 2010s were the Objective-C times, when everybody used MagicalRecord as the Core Data stack wrapper. In 2013, we researched ways to efficiently import data from JSON to Core Data.
We compared popular mapping solutions of that time and this is what we got:
- Build schema: Release. Environment: Xcode 5.1, iPhone 5s, iOS 7
- Unique entities: 3000, total entities: 3000. Entity relationship: Person <->> Phone
- Number of runs: 5
- Cold: import into an empty database
- Hot: import existing objects (i.e. update)
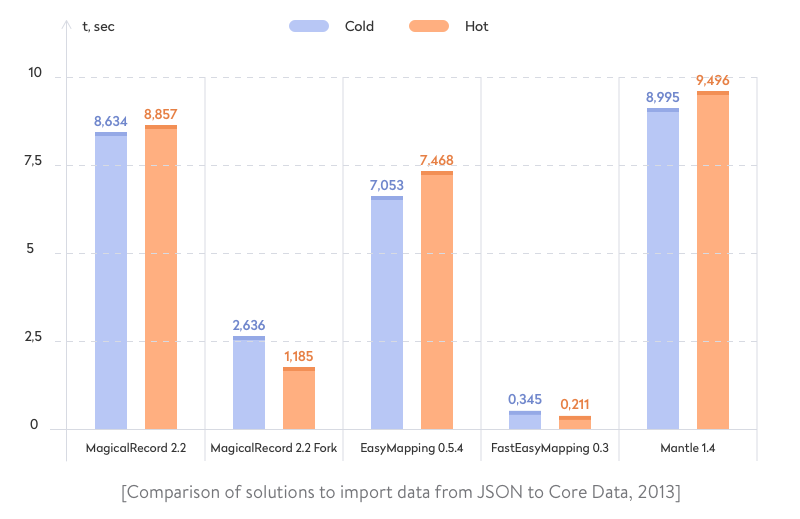
We found that the EasyMappingKit fork known as FastEasyMapping was fast as hell due to some clever optimizations under the hood that we’ll discuss later.
Read also: Is Swift Faster Than Objective-C? Swift 3 and Swift 5 vs Objective-C
Coming back to the present
Let’s now consider two main data import problems: entity uniqueness and mapping rule definitions.
Entity uniqueness
Back in 2013, developers themselves had to write the logic for deciding whether to insert new data as a new entity or to use new data to update an existing entity. What about the modern Core Data framework? It frees developers from such work, as iOS 9 introduced constraints in Core Data.
A constraint is an attribute (or a comma-separated list of attributes) that places unique requirements on an entity. Unique constraints prevent duplication of records in SQLite storage.
How to save JSON data in Core Data? When saving a new record, SQLite checks whether any entity with the same value as the constrained attribute already exists. You may provide constraints for an entity in the NSManagedObjectModel object. This model is used to create a data storage schema, relations between objects, entity validation rules, and constraints used to ensure the uniqueness of entities. So far, the entity uniqueness problem seems to be completely solved by Core Data. We’ll check if it’s really completely solved in a minute.
Definition of mapping rules
Keys may vary between JSON and NSManagedObject. A typical situation is when the backend sends data in snake case (“first_name”: “Jack”). But iOS practice dictates camel case (“firstName”: “Jack”). Consequently, the app should somehow understand how to match “first_name” with “firstName” during the mapping process.
Swift 4 introduced a new way of encoding and decoding data with the Codable API. It enables us to leverage the compiler to generate much of the code needed to encode and decode data to and from a serialized format like JSON.
Let’s experiment with up-to-date solutions to import JSON into Core Data and compare their performance in the case of cold and hot inserts.
Read also: Best Practices for Speeding Up JSON Encoding and Decoding in Go
First experiment: Core Data constraints and Codable
In our first experiment, we’re going to use Core Data constraints to keep data unique and use Codable to decode data from JSON.
Preconditions for all measurements:
- Build schema: Release. Environment: Xcode 11.2, iPhone 7, iOS 13.1
- Unique entities: 3000, total entities: 3000. Entity relationship: Person <->> Phone
- Number of runs: 5
- Cold: import into an empty database
- Hot: import existing objects (i.e. update)
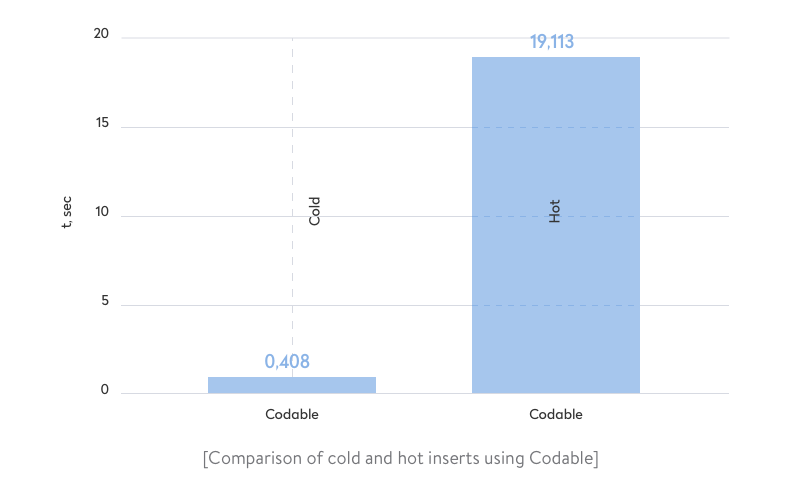
As we can see, the hot import operation becomes pretty expensive in terms of time. Moreover, check out the corresponding memory consumption:
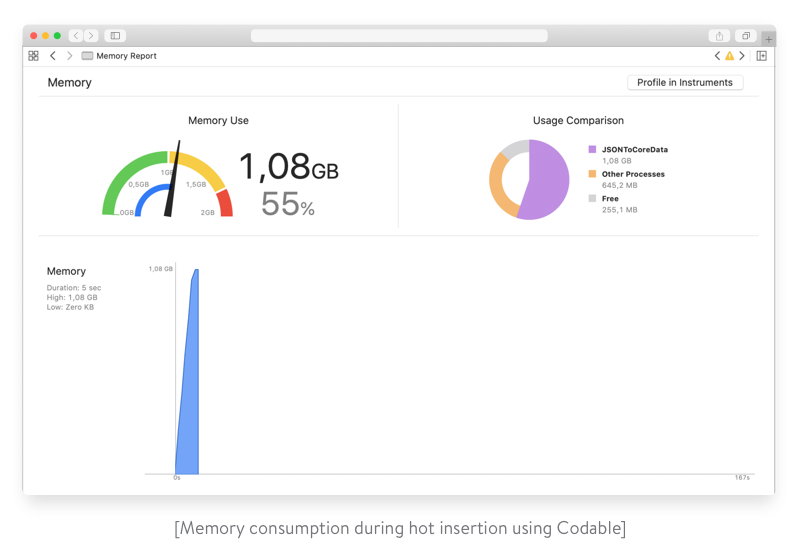
This approach is definitely not efficient and scalable enough in terms of time and memory. Let’s carry on experimenting.
Second experiment: Batches
Apple proposes a solution for importing large data sets. In their code example, they split a data set into batches to avoid a high memory footprint. Let’s try this solution. We’ll use a batch size of 256 as used in the sample code.
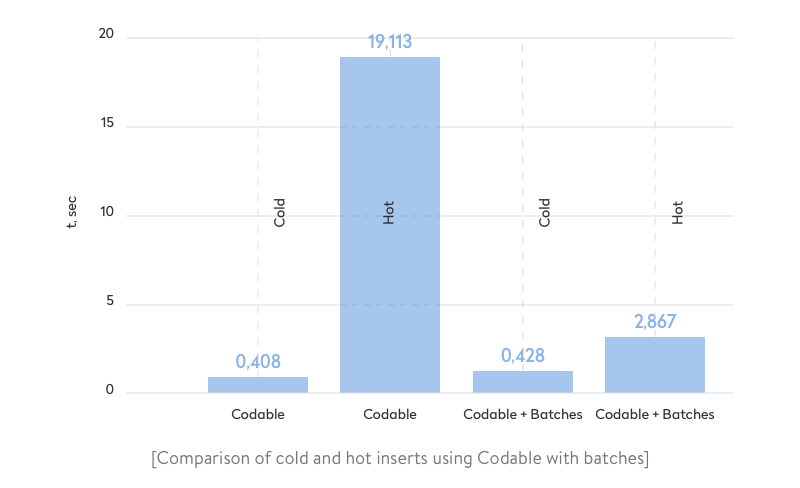
Much better results! Moreover, memory consumption becomes insignificant.
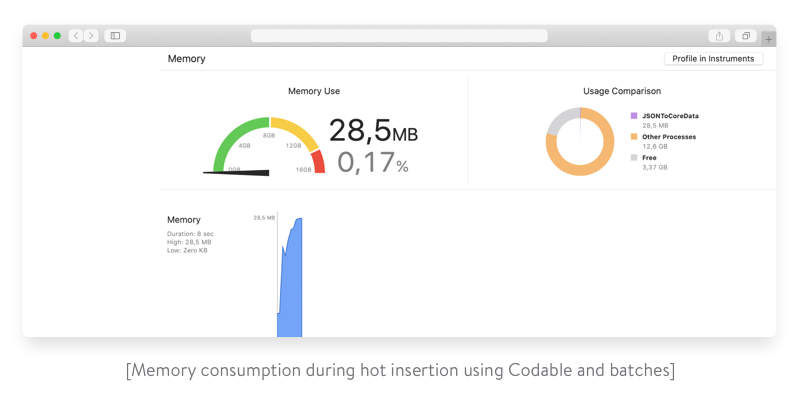
This solution is totally suitable if you don’t face large data sets and the import duration isn’t critical for your application. Just make sure you avoid processing all data as one big batch.
But can we do better? Let’s continue our research.
NSBatchInsertRequest
iOS 13 introduced a new way of inserting data into Core Data storage (SQLite): NSBatchInsertRequest. It works directly with storage at the SQL level, in the same way as NSBatchDeleteRequest and NSBatchUpdateRequest. This helps us avoid all Core Data processing, which means NSBatchInsertRequest has great performance, but with some disadvantages:
No data validation. There are no Core Data validation rules to apply.
Inability to insert/update relations. You can’t manage the relations of inserted entities.
Reflecting changes in fetched data. Since data is changed directly in the storage, changes are not reflected in objects currently in memory. It’s the developer’s responsibility to implement logic for refreshing data.
Inability to define key mapping rules. Keys in the JSON dictionary should be exactly the same as in Core Data entities. But this situation is extremely rare in real projects.
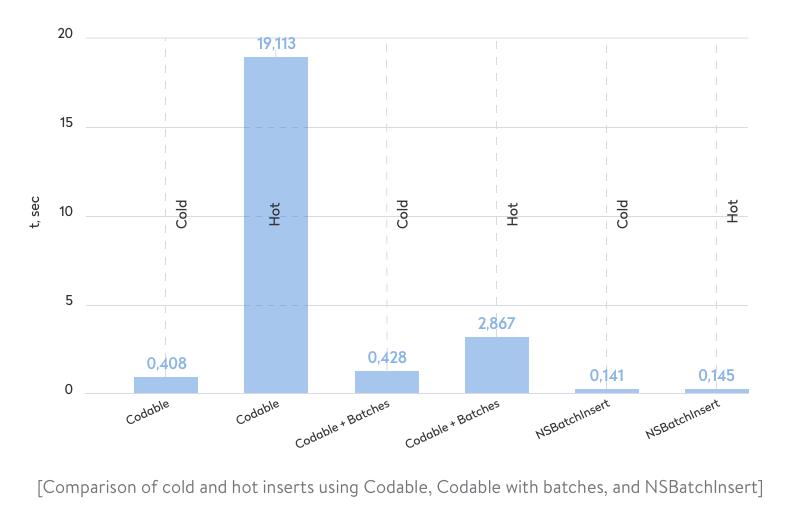
As we can see in the diagram above, NSBatchInsert is extremely fast. Of course, we had to modify our initial JSON to match keys with Core Data entities, and the Phone relation from imported data is totally ignored. This means we actually can’t meet our requirements using this approach.
So far, we can say that the most efficient approach is Codable with constraints over data batches. Now let’s go back to FastEasyMapping and check if it’s still the best option.
Read also: Reactive Programming in Swift
FastEasyMapping
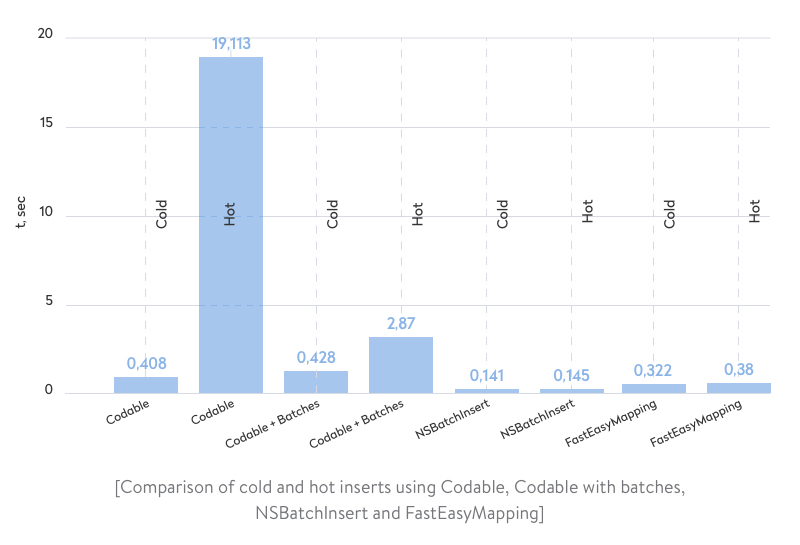
What a surprise! Although FastEasyMapping hasn’t had major improvements since its initial release, the ideas under the hood are still working like a charm. For some reason, in the old measurements, hot inserts took less time than cold inserts. Now we have opposite results. But we hope future releases of FastEasyMapping will fix this issue.
As we can see from the comparison, NSBatchInsert and FastEasyMapping are much faster than ordinary insertions with constraints. Let’s dive into the implementation details to understand the difference.
Looking under the hood: NSBatchInsert, FastEasyMapping, and Codable + constraints + batches
Now it’s time to figure out why the Codable with batches, NSBatchInsertRequest, and FastEasyMapping solutions have different performance. We’ll inspect what happens when performing a cold and hot one-record insert at the SQL level. We’ll pay attention to only the log fragment we’re interested in. This fragment refers to data storage and helps us understand the differences between these solutions.
Codable + constraint
Cold insert
CoreData: sql: INSERT INTO ZPERSON(Z_PK, Z_ENT, Z_OPT, ZATTRIBUTE, ZFIRSTNAME, ZLASTNAME) VALUES(?, ?, ?, ?, ?, ?)
...
Hot insert
CoreData: sql: INSERT INTO ZPERSON(Z_PK, Z_ENT, Z_OPT, ZATTRIBUTE, ZFIRSTNAME, ZLASTNAME) VALUES(?, ?, ?, ?, ?, ?)
...
CoreData: annotation: Optimistic locking failure for ... During updateConstrainedValuesForRow ...
...
CoreData: sql: ROLLBACK
CoreData: sql: SELECT Z_PK, ZID FROM ZPERSON WHERE (ZID IN (? ))
...
CoreData: sql: SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZATTRIBUTE, t0.ZFIRSTNAME, t0.ZID, t0.ZLASTNAME FROM ZPERSON t0 WHERE t0.Z_PK = ?
...
CoreData: sql: UPDATE OR FAIL ZPERSON SET Z_OPT = ? WHERE Z_PK = ? AND Z_OPT = ?
...
CoreData: sql: COMMIT
There’s nothing unusual with the cold insert. The INSERT statement is executed with the necessary parameters. Hot insert is more interesting.
At first, we experience an attempt to execute the same INSERT as executed with the cold Insert, but this attempt ends with an error as the validation of constraints fails. This is predictable, as there’s a record in the storage with the same constrained values we’re trying to insert.
Next, two SELECT statements are executed successively. The first fetches Z_PK (the primary key) for the record that has the same constraints as the one being inserted. The second statement uses the received Z_PK to obtain the corresponding ZPERSON object. After that, the UPDATE statement is executed. UPDATE performs a record update by saving new data in the storage.
One INSERT, two SELECTs, and then an UPDATE statement are executed to perform a hot Update for one record. It’s no wonder the time spent performing this task is significantly longer than the time spent for a cold insert. According to the chart above comparing three cold and hot inserts, it takes 6.5 times longer. Next, we’ll check what happens under the hood of FastEasyMapping.
FastEasyMapping
Cold insert
CoreData: sql: SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZATTRIBUTE, t0.ZFIRSTNAME, t0.ZID, t0.ZLASTNAME FROM ZPERSON t0 WHERE t0.ZID IN (?) LIMIT 1
... returned 0 rows with values: (
)
…
CoreData: sql: INSERT INTO ZPERSON(Z_PK, Z_ENT, Z_OPT, ZATTRIBUTE, ZFIRSTNAME, ZLASTNAME) VALUES(?, ?, ?, ?, ?, ?)Hot insert
CoreData: sql: SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZATTRIBUTE, t0.ZFIRSTNAME, t0.ZID, t0.ZLASTNAME FROM ZPERSON t0 WHERE t0.ZID IN (?) LIMIT 1
... returned 1 rows with values:
...
CoreData: sql: UPDATE OR FAIL ZPERSON SET Z_OPT = ? WHERE Z_PK = ? AND Z_OPT = ?
...
When configuring FastEasyMapping, you need to state which object property is the primary key. Then FastEasyMapping executes one SELECT statement for all primary JSON keys to receive the records that need to be updated.
Then, depending on whether a record is already in the storage, FastEasyMapping executes either INSERT (in the case of a cold insert) or UPDATE (in the case of a hot insert). Plain and simple! Thanks to the minimization of SELECT statements, less time is spent performing a hot insert.
NSBatchInsertRequest
Cold insert
...
CoreData: sql: INSERT INTO ZPERSON ... ON CONFLICT(ZID) DO UPDATE ...
…
Hot insert
...
CoreData: sql: INSERT INTO ZPERSON ... ON CONFLICT(ZID) DO UPDATE ...
…
As we can see, BatchInsert executes the fewest INSERT and UPDATE statements for records in storage. That’s why BatchInsert has the best performance.
Conclusion
Despite its disadvantages described above, NSBatchInsertRequst is native to iOS, which means there’s no dependence on third-party developers. It’s also an extremely effective solution for saving JSON to Core Data in case of large volumes of data. It’s worth using if you don’t support iOS versions earlier than iOS 13 and if you deal with lots of data with no relations to other entities.
Codable with constraints and batches is a great formula to follow and is also native to iOS. This approach is less efficient, but if the performance is bearable or if you’re not dealing with much data, feel free to apply it.
FastEasyMapping supports the same functionality as Codable with constraints and batches. Thanks to its efficient work with SQL, FastEasyMapping runs faster. FastEasyMapping has only one disadvantage: dependence on a third-party tool.
Ten articles before and after
How to Validate In-App Purchases On-Device and Through a Client’s Own Server
Smart Home Automation for Android on the Example of ZigBee and Z-Wave
Why You Should Not Use Telegram Open Source Code
Best SEO Practices for React Websites
Android Studio Plugin Development
Measuring Code Quality: How to Do Android Code Review
Detailed Analysis of the Top Modern Database Solutions